Mixed Factorial ANOVA in R
Load Required Packages
library(afex)## Loading required package: lme4## Loading required package: Matrix## ************
## Welcome to afex. For support visit: http://afex.singmann.science/## - Functions for ANOVAs: aov_car(), aov_ez(), and aov_4()
## - Methods for calculating p-values with mixed(): 'S', 'KR', 'LRT', and 'PB'
## - 'afex_aov' and 'mixed' objects can be passed to emmeans() for follow-up tests
## - NEWS: emmeans() for ANOVA models now uses model = 'multivariate' as default.
## - Get and set global package options with: afex_options()
## - Set orthogonal sum-to-zero contrasts globally: set_sum_contrasts()
## - For example analyses see: browseVignettes("afex")
## ************##
## Attaching package: 'afex'## The following object is masked from 'package:lme4':
##
## lmerlibrary(tidyr)##
## Attaching package: 'tidyr'## The following objects are masked from 'package:Matrix':
##
## expand, pack, unpackData Description
The fictional data set is part of the data library of the JASP software, and is from the book by Field (2017)1. Here it only contains a subset of the data, where 10 men and 10 women for three speed-dating partners. All three partners were low in attractiveness (however defined), but varied in charisma: high, some, or none.
Data Import
charisma_data <- read.csv("charisma_ugly.csv")
# Show the first six rows
head(charisma_data)Mixed ANOVA
In R, one needs to first convert the data to a long format, so that each row represents an observation (instead of a person). In this data, there were 60 observations.
# First, convert to long format data
long_data <- tidyr::pivot_longer(
charisma_data,
cols = ug_high:ug_none,
# name of IV
names_to = "charisma",
# remove the "ug_" prefix
names_prefix = "ug_",
# name of DV
values_to = "rating"
)
long_datamixed_anova <- aov_ez(
id = "participant",
dv = "rating",
data = long_data,
between = "gender",
within = "charisma"
)## Converting to factor: gender## Contrasts set to contr.sum for the following variables: gendertest_sphericity(mixed_anova)## Warning: Functionality has moved to the 'performance' package.
## Calling 'performance::check_sphericity()'.## Warning in summary.Anova.mlm(object$Anova, multivariate = FALSE): HF eps > 1
## treated as 1## OK: Data seems to be spherical (p > 0.612).When one or more independent variable is a within-subject variable, mixed or repeated-measure ANOVA requires testing the assumption of sphericity. Here, the Mauchly’s test of sphericity provided insufficient evidence that the assumption of sphericity was violated, \(p = .612\).
ANOVA Table
mixed_anova## Anova Table (Type 3 tests)
##
## Response: rating
## Effect df MSE F ges p.value
## 1 gender 1, 18 25.42 71.82 *** .586 <.001
## 2 charisma 1.89, 34.09 24.42 167.84 *** .857 <.001
## 3 gender:charisma 1.89, 34.09 24.42 58.10 *** .676 <.001
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1
##
## Sphericity correction method: GGNote that the result by default applies the Greenhousse-Geisser correction for violations of the sphericity assumption, but since the Mauchly’s test was not statistically significant, the results would be similar with or without the correction. Also note that the result here reports the generalized \(\eta^2\) (the ges column), which is different from some other software. See the documentation of the ?afex::nice page.
Plot
afex_plot(mixed_anova, x = "charisma", trace = "gender")## Warning: Panel(s) show a mixed within-between-design.
## Error bars do not allow comparisons across all means.
## Suppress error bars with: error = "none"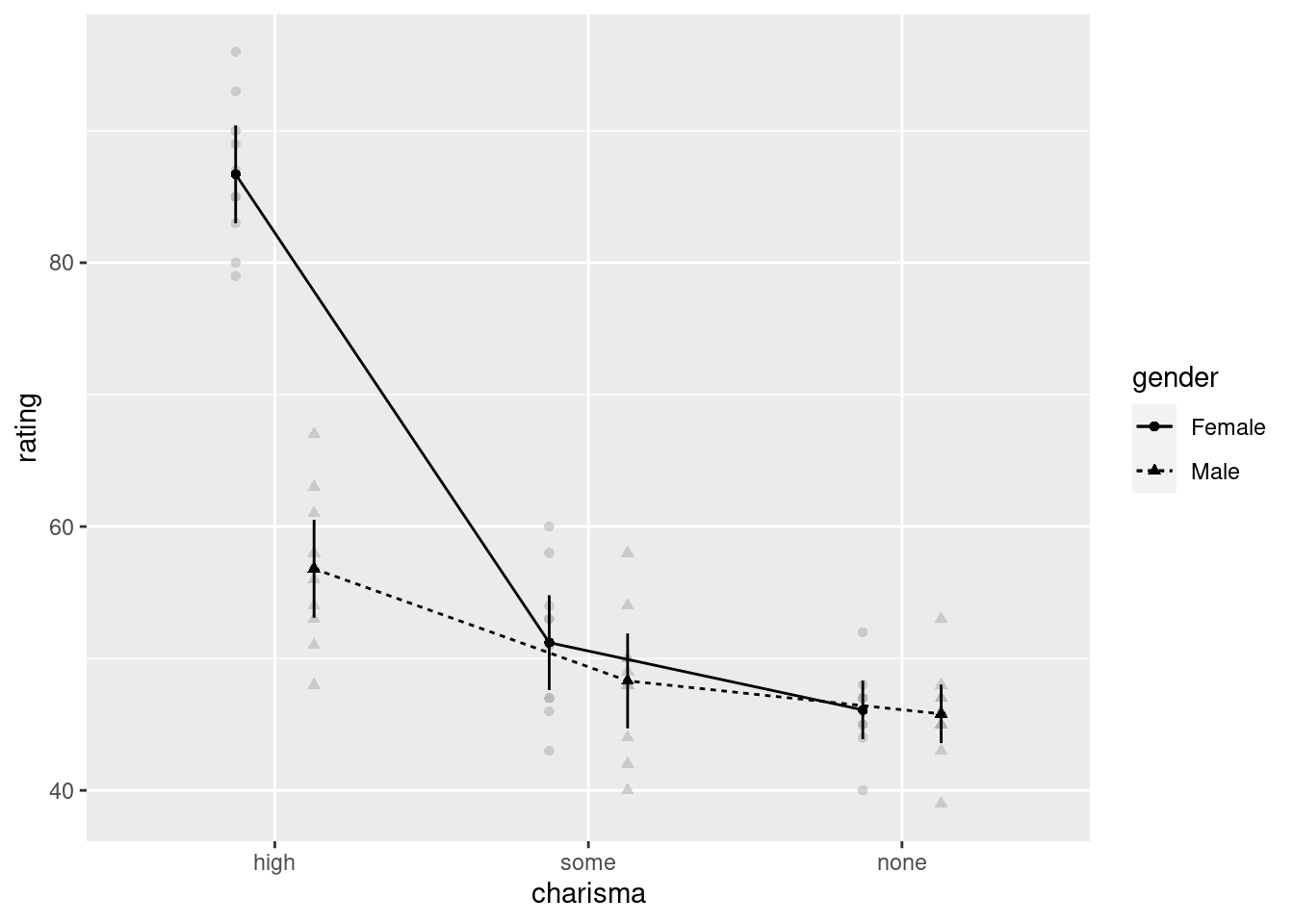
Sample Result Reporting
| Effect | \(\hat{\eta}^2_G\) | 90% CI | \(F\) | \(\mathit{df}^{\mathrm{GG}}\) | \(\mathit{df}_{\mathrm{res}}^{\mathrm{GG}}\) | \(p\) |
|---|---|---|---|---|---|---|
| Gender | .586 | [.311, .739] | 71.82 | 1 | 18 | < .001 |
| Charisma | .857 | [.781, .899] | 167.84 | 1.89 | 34.09 | < .001 |
| Gender \(\times\) Charisma | .676 | [.516, .768] | 58.10 | 1.89 | 34.09 | < .001 |
A two-way mixed ANOVA was conducted, with gender (female vs. male) as the between-subject independent variable and charisma (high, some, none) as the within-subject independent variable. There was a significant main effect of charisma, \(F(1.89, 34.09) = 167.84\), \(p < .001\), \(\hat{\eta}^2_G = .857\), 90% CI \([.781, .899]\). As shown in the figure, overall female participants provided a higer rating than male participants. There was also a significant main effect of gender, \(F(1, 18) = 71.82\), \(p < .001\), \(\hat{\eta}^2_G = .586\), 90% CI \([.311, .739]\). As shown in the figure, ratings were higher for partners who had high charisma. Finally, there was a significant charisma \(\times\) gender interaction, \(F(1.89, 34.09) = 58.10\), \(p < .001\), \(\hat{\eta}^2_G = .676\), 90% CI \([.516, .768]\). As shown in the figure, while the ratings were similar between female and male participants for partners who had some or no charisma, female participants gave higher ratings for the partner with high charisma, as compared to male participants.
Field, A. P. (2017). Discovering Statistics Using IBM SPSS Statistics (5th ed.). Sage.↩︎
Yuan Bo 袁博
Associate Professor of Psychology (Social Psychology)
My research examines the nature and dynamics of social norms, namely how norms may emerge and become stable, why norms may suddenly change, how is it possible that inefficient or unpopular norms survive, and what motivates people to obey norms. I combines laboratory and simulation experiments to test theoretical predictions and build empirically-grounded models of social norms and their dynamics.